The Many Different Forms of Concurrency and Parallelism



Modern software design requires the understanding of the different layers of concurrency and parallelism that can exist. Abstractions exposed by libraries and frameworks can inadvertently hide layers of parallelism when their focus is the simplification of others; and libraries trying to treat all levels of parallelism equality can be limited to low level concepts for their common interface. In order to optimally design and avoid errors, all levels of concurrency and parallelism need to be understood no matter what framework is chosen.
The Basic Idea of Parallelism
Parallelism is a simple concept: multiple computer operations performed at the same time. This requires separate CPU hardware, such as separate cores in a CPU, separate CPUs, or even separate computers.
ⓘ There is the concept of SIMD (single instruction, multiple data) parallelism, but these hardware instructions have specific applications and not a general application
Concurrency is a separate but related concept: it is the ability to break up work into separate tasks. Parallelism
requires concurrency, but concurrency doesn’t require parallelism. Concurrency is managed by the OS as a Thread, but
it can also be managed internally within application code. But only OS threads can be executed in parallel by the OS,
as threads are how the OS sends code for executing by the CPU. Any concurrency internal to the application can’t be
executed in parallel unless it is also being partitioned into separate OS threads.

Elements of the stream can come from multiple sources, threads running concurrently and in parallel. A stream will present data being produced concurrently as a more convenient serial representation, since the stream will only ever have 1 head element at a time, with the rest queued until ready to be acted on.

Elements of a stream can then be processed concurrently and in parallel by consumers working in separate threads.
Pitfalls of Parallelism
A simple example of a parallelism pitfall is the increment operator +=, (i = i + 1).
Even though += is a simple low-level operator it is not thread safe. When executed in parallel with a standard global
variable i the resulting value of i is indeterminate. It won’t always equal the number of iterations. In a loop
run 30 times, i will often equal less than 30.
The explanation is how computers parallelize execution. Each concurrent += operation runs in its own hardware with an
input value i. When 2 parallel operations of += start at the same time they both start with the same value of
i! Essentially i += 1 cannot be parallelized because each execution depends on the previous execution’s result.
The avoid this pitfall access to i must be sequential or able to detect modifications to i when threads attempt to
merge back in their changes. Serialization techniques exist, such as the Stream above which is prominent in
the Actor Model, or code can wait to execute using locks (syncronized or
by way of a semaphore. There conflict detection techniques
such as transactions
or Software Transaction Memory (STM).
Forms of Parallelism
From the perspective of a network service, there can be multiple forms of parallelism. Consider a distributed system handling HTTP requests in a serverless cloud environment such as GCP Cloud Functions or AWS Lambda.
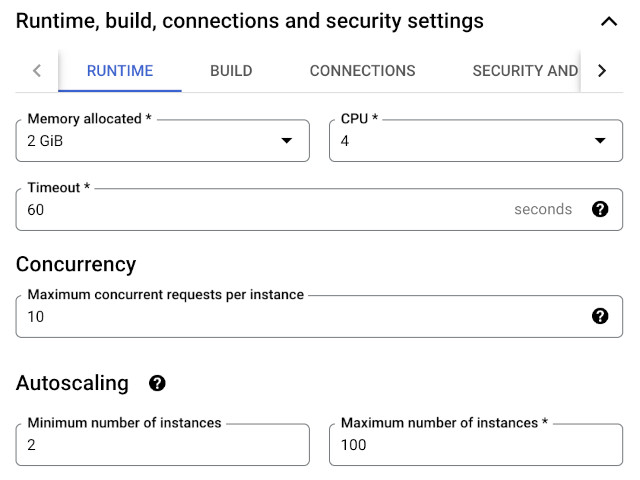
There are 3 settings in GCP that affect parallelism and concurrency:
CPUMaximum concurrent requests per instanceMinimum number of instances/Maximum number of instances
CPU
This represents the number of local (virtual) cores available for code execution. This may or may not match the number of underlying hardware cores, often vCPU are hyper-threaded or a fraction of a hardware core shared with other tenants. Whether a dedicated hardware core or not, the same optimizations apply with the goal of achieving a desired usage % with minimal OS thread switching.
Optimal CPU Usage % and Load
There are different optimal CPU usage % for different workloads. A 100% usage will achieve the greatest throughput of executed instructions, by maintaining a deep queue of work waiting to execute. Any time code execution is queued, the time in queue is latency introduced into the system. Batch and background workloads are often latency insensitive making 100% CPU usage targets optimal, but software systems benefiting or requiring low latency execution will necessitate targeting CPU usage percentages < 100%.
GCP Scaling based on CPU utilization has a warning
Caution: If your application takes a long time to initialize on new VMs, Google recommends that you do not set a target CPU utilization of 85% or above. In such a case, if your application sees an increase in traffic, your MIG’s CPUs might be at risk of getting overloaded while your application slowly initializes on the new VMs that the autoscaler adds.
CPU Load is measurement of the contention for the hardware. Optimally the CPU Load will be equal to the number of
cores available, for an 8 core machine a CPU load of 8 will mean each core will typically be executing code without
any code having to wait for an available core. A CPU Load < 8 would mean idle cores, and > 8 would mean tasks waiting
for execution.
ExecutionContext and Context Switching
Context Switching refers to whenever the executing thread changes on CPU hardware. This process incurs a penalty
for the duration of time required to load new thread CPU instructions and cache from memory. Every OS thread switch
consumes time when the CPU cannot execute code, and this is reported as % of CPU utilization.
Concurrency libraries can offer workarounds utilizing green threads or
with similar concepts of code partitioning that share a single OS thread. In the Java and Scala ecosystem, the
ExecutionContext is a mechanism to selecting an Executor defining how concurrent code is assigned to threads. Scala
ExecutionContext.Implicits.global defaults to a Fork/Join executor that attempts to balance context
switching by maintaining thread affinity when possible but still allowing work-stealing and reassignment to prevent idle
cores.
It is interesting to note the requirement of an ExecutionContext on the Scala Future map. This indicates that every
map or flatMap can perform a context switch under non-ideal conditions. Concurrency libraries such
as ZIO
and Twitter Futures have runtimes build to avoid
an ExecutionContext requirement and penalty, and Akka as implemented their own same-thread Executor to work around it
while continuing to use the Scala Future construct.
TODO: link to Akka sameThread Executor
Maximum concurrent requests per instance
As the name implies, this GCP parameter controls the level of concurrency. Without sufficient concurrency parallel executors will idle. As mentioned above in Optimal CPU Usage % and Load too much concurrency will be penalized by context switching overhead.
Thread-Per-Request Frameworks
The standard software approach to handling concurrent workloads is a thread-per-request model. For a web framework this means assigning an OS thread to the request execution until the response is sent back to the client. For a SQL database driver, this means assigning a thread to the network connection for the entirety of the session. This reduces complexity in userspace by leveraging OS level security, scheduling, and memory management.
It can be assumed each concurrent request will use at least 1 thread, meaning at minimum the maximum concurrent requests per instance parameter should be at least equal to the number of CPU to prevent cores going idle. An exception are requests which create threads with parallel execution, or if background processes exist which benefit from a dedicated core, such as a database running on the same physical hardware as a webserver. Not all threads require parallel execution, it is frequent to create threads which block, as in they will become dormant for periods as they wait for external input. Blocked threads run concurrently, but not in parallel since they are not actively consuming CPU time.
Performance tuning concurrency is primarily ensuring active threads execute and terminate fast enough to not grow without bound, as each consumes additional CPU and memory overhead. Primary configuration metrics are hardware related, scaling vertically (adding more vCPU) or horizontally (adding more server instances).
A notable exception to the thread-per-request model is the use of virtual or green threads, as introduced by Project Loom in JDK 21. This case more closely behaves as a non-blocking approach, discussed below.
Thread-Sharing Frameworks (Non-Blocking)
An alternative approach to OS thread-per-request is known as non-blocking. This approach brings concurrency management into the scope of the application, allowing application framework code to optimally assign thread execution within groups of threads, called thread-pools. This eliminates lower level OS calls and reduces thread resource overhead.
Common JVM non-blocking frameworks are WebFlux and Play, with supporting libraries Java NIO and Project Reactor, and the SQL driver R2DBC.
Performance tuning a thread-per-request model involves defining and allocating thread-pool sizes, as well as the
Executor for the thread pools, which is the application code in charge of assigning code to threads from the pool.
Adding further complexity is managing any legacy code that follows a blocking paradigm; standard configuration is
creating yet another thread-pool specifically for blocking code to execute. Common problems are inadvertently blocking
within a non-blocking code segment, which will effectively cause idle CPU during the duration of the block.
Additional complexity is necessarily introduced into user application code, with the necessary wrapping of all function return values within special class types to indicate an async continuation.
Similar to a batch or background task, the non-blocking framework will most closely achieve Mechanical Sympathy of matching software and hardware. Thread pools can be created and limited such that no excess threads are created, and the approach encourages a high level of interrupter concurrency achieving efficient parallelism and CPU utilization.
(Minimum / Maximum) number of instances
Often the first 2 GCP parameters, CPU and Concurrent Requests per Instance will depend on the software design used, and this parameter will depend on the system load. With this in mind, variable load will result in a variable number of instances. Cloud platforms expose this as Autoscaling.
Distributed Concurrency
The concurrency required to take advantage of multiple instances is different from the currency required to take
advantage of multiple cores. Distributed Concurrency introduces many new concerns that are not present when designing
around Local Concurrency.
Distributing data is no longer a single copy or always available.
These concerns are complicated topics categorized as Strong versus Eventual Consistency and the CAP Theorem, respectively.
Within the scope of this article it is noted that certain types of software problems are more easily designed for distributed concurrency, such as web requests and event-based processing. There is never a guarantee problems of any type can be solved using distributed computing, but often harder-to-distribute concerns such as atomic state transitions and transactions can be externalized into separate systems leaving a cleanly distributed core problem.
A typical HTTP web application is implemented using a highly concurrent stateless web-tier, with offloading of state and strongly consistent data to separate microservices, which may or may not be distributed.
Optimal Configurations
Having Multiple Thread-pools Is Unavoidable
Optimal mechanical sympathy and efficient context-switching will match threads to cores one-to-one, however unavoidable reasons exist making to make this impossible. When using a non-blocking framework, the worker thread-pool shouldn’t run blocking code requiring creation of a separate pool. Libraries responsible for logging, caching, and monitoring define their own worker threads to allow seamless execution in the background. The JVM garbage collector continuously runs in parallel threads.
Load Testing and Pragmatic Observation
All settings should be pragmatically tuned according to real-world performance under a variety of workloads. The many
levels of parallelism and concurrency can compete for resources in unexpected ways with non-linear response to varying
load conditions. Optimizing local thread parallelism by way of thread-pool families, sizes and Executor, and
distributed parallelism layer by way of hardware and traffic shaping have deep implications that cannot be solved with
a silver-bullet of a software framework or feature.


